One of the JNCIE-SP exam objectives I found difficult was hub and spoke VPN. Conceptually it’s not easy, and as is often the case, the documentation is only somewhat helpful. This series of posts is designed to walk you through the concepts of hub and spoke VPN, as well as its basic configuration using BGP, and then OSPF as the PE-CE protocol. Finally I will talk about route reflector issues when using H/S VPN. It is an important topic to master for your JNCIE exam, and if properly explained you will find it’s not as difficult as it seems. This article assumes you are familiar with basic configuration of Layer 3 MPLS VPN, including vrf import and export policies.
Note: I recommend that you only use vrf import/export policies for the JNCIE lab and avoid the vrf-target command for layer 3 VPN.
We’ll take a simple example topology with three sites. Normally, if these sites are configured in a Layer 3 MPLS VPN, site 1 and site 2 are able to talk directly over the MLPS network. That is, the traffic between site 1 and site 2 is never seen by the hub site.
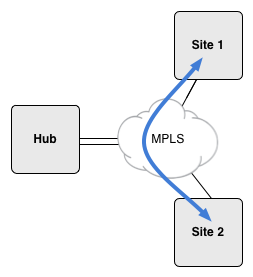
This is, of course desirable. Routing the site-to-site traffic through a central site could produce significant delays, especially if the geographic distance between the sites is large. It also would consume bandwidth unnecessarily on the hub interfaces. By default MPLS VPNs avoid this behavior.
Hub and spoke VPN changes this model and actually routes the spoke-to-spoke traffic through the hub site.
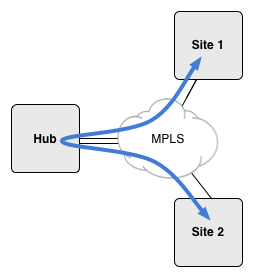
Given the above paragraph, why would anybody want to do this? Well, I would give you the caveat that for expert-level certification exams, you should not spend too much time asking why. Nevertheless, one reason you might use this configuration is to apply some sort of monitoring to the spoke-to-spoke traffic.
You will notice that the hub site has two interfaces. Whether physical or logical, the hub site will need to have two interfaces.
We’re going to blow the picture up a bit, and put some actual routers in to flesh out the picture, and then we are going to look at how the control plane works.

Site 1 CE advertises a route (172.255.255.9) to its PE. The PE router then advertises the route via MBGP to the hub PE. The hub PE then advertises it over the top link to the hub CE. The hub CE learns the route and then re-advertises it back to the same PE it learned it from. If you haven’t seen h/s VPN before this may confuse you, but here comes the trick: the two interfaces that connect the hub CE to the hub PE are in different VRFs. Therefore, the hub PE will have a copy of the 172.255.255.9 route in both VRFs. This is the part which makes it a bit confusing.
The hub PE, having re-learned the route from the hub CE, then advertises it out to the site 2 PE, which sends it on its way to the site 2 CE. Since site 2’s route came from the hub PE via the hub CE, the route actually is pointing along the path through the hub site. As a result of this hocus-pocus, the data plane will forward through the hub site. To achieve this we will need to define specific route export/import policies on the PEs and do some cross-VRF importing, as illustrated below.

The spoke PEs do not learn routes directly from each other, but instead only learn routes that have been re-advertised by the hub site. Therefore, they will only import routes into their VRF that have the hub VRF target. They will not, repeat, will not import routes from the spoke VRF target. This may be counterintuitive because they are not importing routes with their “own” VRF target. However, this is how we achieve the cross-VRF importation. Even though they do not import routes with their own target, they do export with it. All routes exported from the spoke sites have the spoke target.
The hub PE is even more complex. It has two VRFs. The spoke VRF imports routes that have the spoke target, but it doesn’t export anything. That’s because we want to force the spoke sites to pull from the hub VRF. No routes are exported from the spoke. Meanwhile the hub instance does not import anything at all. It pulls no routes from MBGP or the other PEs. Instead, any routes in its table (aside from interface routes) it learns from the hub CE. Unlike the spoke, however, it does export routes, which are tagged with the hub VRF target. It is this target that the spokes accept.
In my next article you will see how we configure a null policy to achieve these goals. In the meantime, a little memory trick helped me to configure this. On the hub router, the spoke instance imports but does not export. I named my import policy “spoke-in” which sounds a bit like Spokane, the city. It may not be the greatest memory trick, but you can remember all the rest of the hub PE policies if you remember this. Remember, each VRF has a “null” policy, and they are the opposite of each other. So, if the spoke has an import policy (“spoke-in”), its export policy must be null, and therefore the import policy for the hub must be null and it must have an export policy (“hub-out”). This will become clearer in future articles when I explain the configuration if it’s not clear now.
To summarize this article:
- Hub and Spoke MPLS VPN routes traffic through a hub site instead of directly between spokes.
- To achieve this, the control plane (i.e. routing) also follows a hub and spoke model.
- The spoke routers import and export from different hub PE VRFs.
- The hub PE has two VRFs, one for sending routes to the hub CE and one for receiving them.
Look forward to the next article which will explain how to configure this with BGP as the PE-CE routing protocol.